


Top Local LLM Runtimes to Run Large Language Models Locally: A Hands-on Guide for Developers
Explore the best tools like Ollama, LM Studio, and GPT4All to run open-source LLMs privately and offline on your laptop — with features, setup guides, use cases, and real-world examples.

Large Language Models (LLMs) have transformed AI — but relying on cloud services for every interaction may raise concerns around privacy, cost, and latency.
The good news? Today’s tools let you run powerful LLMs entirely on your local machine — from chat assistants to code generators — even on a laptop!
This article will walk you through the top tools, their features, use cases, and how to get started step-by-step — with real examples.
Top Tools to Run LLMs Locally
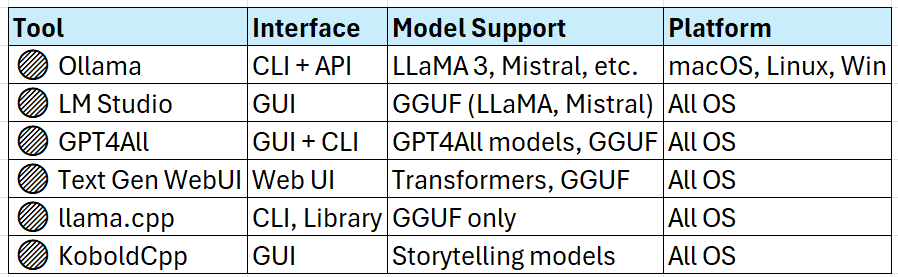
Use Cases
Private Chatbots – no cloud API needed.
RAG Applications – fetch documents and summarize locally.
Coding Assistants – pair with LLaMA or CodeLLaMA.
Offline Research Agents – analyze PDFs, papers, and data.
Fine-Tuning & LoRA Models – personalize models for tasks.
Key Features Comparison
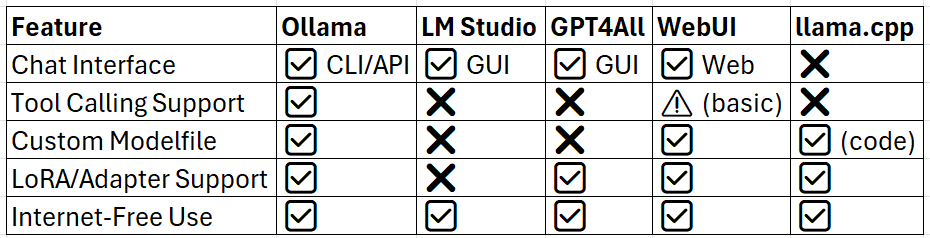
Popular Local LLM Runtimes
1. LM Studio
What it is: GUI-based LLM runner with local model support.
Key Features:
Easy-to-use desktop app (no command line needed).
Download and run models like LLaMA, Mistral, GPT-J, etc.
Uses
ggml,gguf, orexllamaformat models.Integrated chat interface.
OS: macOS, Windows, Linux
Link: https://lmstudio.ai
How to Download a Model:
Open LM Studio app.
Go to the “Models” tab (left sidebar).
Search for a model (e.g.,
mistral,llama3).Click “Download” next to your chosen model (prefer a
.ggufformat with quantization likeQ4_K_M).
How to Load and Chat:
Go to the “Chat” tab.
Choose your downloaded model from the dropdown.
Type your prompt and press Enter.
Example: “Explain how neural networks work.”
2. Ollama
What it is: CLI and API-based local LLM runtime for running open-source models offline with advanced developer features.
Key Features:
Command-line tool and OpenAI-compatible API for local inference
Run models like LLaMA 3, Mistral, Gemma, Qwen, etc.
Supports tool/function calling, Modelfiles, and LoRA adapters
Uses efficient GGUF format for quantized models
API-ready for integration into Python apps, LangChain, and RAG systems
Privacy-focused: no internet needed after downloading models
OS: macOS, Windows, Linux
Link: https://ollama.com
How to Download a Model:
Open PowerShell or Terminal and run:
ollama pull llama3
ollama pull llama3.3
ollama run llama3.3
ollama run gemma3:1b
ollama list # See installed models
ollama show llama3.3 # View model info
ollama pull gemma3
ollama pull mistral
ollama run mistralStart chatting in the terminal:
>>> What is the capital of India?How to Use in Python (API Access):
from langchain_ollama import OllamaLLM model = OllamaLLM(model="llama3") print(model.invoke("Summarize AI ethics."))using OpenAI-compatible API:
import openai
openai.api_key = "ollama"
openai.base_url = "http://localhost:11434/v1"
response = openai.ChatCompletion.create(
model="llama3",
messages=[{"role": "user", "content": "What is machine learning?"}]
)
print(response['choices'][0]['message']['content'])
3. GPT4All
What it is: An open-source desktop app and CLI that enables local inference with open-source LLMs — ideal for privacy, offline use, and ease of setup.
Key Features:
Easy-to-use desktop app with built-in chat interface
Works fully offline after model download
Supports popular GGUF models (e.g., Mistral, LLaMA, Falcon, Qwen)
Also provides a local REST API for integration with custom apps
Cross-platform: Windows, macOS, Linux
Stores all data locally, ensuring data privacy
Ideal for experimenting, chatting, summarizing, and offline research
OS: Windows, macOS, Linux
Link: https://www.nomic.ai/gpt4all
How to Download a Model:
Launch GPT4All Desktop App.
From the home screen, click “Download Models”.
Select a model (e.g.,
mistral-7b-instruct.gguf).Click Download and wait for it to finish.
How to Start Chatting (GUI):
Choose your model in the left pane.
Start typing into the chat box.
Example: “Translate this to French: Hello, how are you?”
CLI (Optional):
From terminal:
./gpt4all-lora-quantized-win.exe --model ./models/mistral.ggufThen interact in the terminal.
4. Text Generation WebUI
What it is: A powerful, web-based user interface to run a wide variety of LLMs locally using multiple backends (Transformers, GGUF, ExLlama, GPTQ).
Key Features:
Web-based UI accessible in browser (
localhost:7860)Supports multiple model formats: GGUF, Transformers, GPTQ, ExLlama
Highly customizable: prompt templates, LoRA support, settings control
Multi-user support, extensions (character AI, RAG, RP modules)
Active open-source community
OS: Windows, macOS, Linux
Link: https://github.com/oobabooga/text-generation-webui
How to Download a Model:
Clone the repo:
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webuiRun the installer (for Windows):
python download-model.pyChoose a model like
mistral-7b-instruct.Q4_K_M.gguf
llama2-13b-chat.Q5_K_S.ggufHow to Run and Chat:
Start the WebUI:
python server.py --model <your-model-path>Open browser and visit: http://localhost:7860
Enter your prompt and start chatting.
5. llama.cpp
What it is: A low-level C++ library for running GGUF quantized models on CPUs and lightweight systems. Forms the backend for many local LLM tools like Ollama and LM Studio.
Key Features:
Extremely fast, optimized for CPU usage
Runs quantized models (GGUF)
Works on Windows, Linux, macOS, and even Android & Raspberry Pi
Used in headless, embedded, or CLI environments
No external dependencies
OS: All OS (cross-platform)
Link: https://github.com/ggerganov/llama.cpp
How to Download & Run:
Clone and build:
git clone https://github.com/ggerganov/llama.cpp cd llama.cppDownload GGUF model from Hugging Face (
TheBloke):
Place it in
/models
Run a prompt:
./main -m models/llama3-8b.Q4_K_M.gguf -p "Write a haiku about summer."No GUI – strictly CLI
Use for scripting, embedding, or building your own UI.
6. KoboldCpp
What it is: A fast, GPU-accelerated local LLM runner optimized for storytelling, roleplay, and creative writing, with GGUF model support and GUI.
Key Features:
GUI interface focused on story generation
Runs GGUF models (supports llama.cpp backend)
Highly configurable character/author tools
Used widely in text adventure and fan fiction communities
Integrated memory, context settings, and style presets
OS: All OS
Link: https://github.com/LostRuins/koboldcpp
How to Use:
Download a GGUF model (e.g.,
mistral,llama2, etc.)Run the
koboldcpp.exeor equivalent scriptGUI will launch in browser (or run as a local app)
Built-in GUI:
Offers text-box based storytelling UI with memory + persona config.
7. Faraday.dev
What it is: A developer-focused platform for building and testing private RAG pipelines and LLM backends locally with customizable UI and data connectors.
Key Features:
Visual UI for building LLM+data pipelines
Plug in your own GGUF/OpenAI-compatible models
Connect local PDF/CSV/Markdown files for RAG
Powerful for prototyping and testing AI workflows
Works locally or inside Docker containers
OS: All OS (via Docker)
Link: https://faraday.dev
How to Use:
Install Docker
Run Faraday container:
docker run -it -p 3000:3000 faradayai/faradayOpen browser: http://localhost:3000
Load your model (e.g., Ollama, OpenRouter) and plug in documents
Visual Interface:
Drag-and-drop to create pipelines (e.g., Input → Embedder → Retriever → Model)
What Is GGUF Format?
If you're new to running large language models (LLMs) locally, you'll frequently encounter the term GGUF — and for good reason.
GGUF stands for "GPT-GGML Unified Format", and it's the standard model format used by most local LLM runtimes today — including Ollama, LM Studio, GPT4All, llama.cpp, and Text Generation WebUI.
Why GGUF Matters
Originally, LLMs like LLaMA, GPT-J, and Mistral were released in full-precision formats (FP16/FP32) that required powerful GPUs with 40+ GB of VRAM. Running these on personal machines was nearly impossible.
GGUF solves this by introducing:
✅ Quantization: Reduces model size without major performance loss
✅ Fast loading: Optimized for CPU and GPU inference
✅ Hardware-friendly: Can run on a typical laptop (even without GPU)
✅ Standardization: Works across all major local inference tools
GGUF vs Traditional Formats

Where to Find GGUF Models
The most popular source for high-quality, ready-to-use GGUF models is:
👉 Hugging Face – TheBloke’s Model Repository
You'll find quantized versions of:
LLaMA 2 & LLaMA 3
Mistral, Mixtral
Gemma, Qwen, Phi-2
WizardCoder, Dolphin, Orca
Example GGUF Model Names
llama3-8b-instruct.Q4_K_M.ggufmistral-7b-instruct.Q5_K_M.ggufgemma-2b-it.Q4_K_M.gguf
Tip
If a tool says "load a GGUF model", it means:
Download a
.gguffile from Hugging FaceSelect a quantization level that fits your RAM (Q4_K_M is a good default)
Load it in your tool of choice (Ollama, LM Studio, etc.)
Recommendation for You
If you want:
Beginner-friendly with chat UI → 🟢 LM Studio or GPT4All
Advanced control + browser UI → 🟢 Text Generation WebUI
Terminal + API + privacy → 🟢 Ollama
Core library usage → 🟢 llama.cpp
RAG and Dev Use → 🟢 Faraday.dev
Benefits of Running LLMs Locally
Privacy-first: Your data stays on your machine.
No API costs: Great for developers and hobbyists.
Faster response times: No internet latency.
Customizable: Tune with LoRA or adapters.
Learning and experimenting: Explore the models deeply.
Summary

Final Thoughts
Running LLMs locally has never been more accessible.
Whether you're a developer building AI tools, a researcher experimenting with RAG, or just curious about LLMs — tools like Ollama, LM Studio, and GPT4All make it easy, free, and secure.
For more in-depth technical insights and articles, feel free to explore:
Girish Central
LinkTree: GirishHub – A single hub for all my content, resources, and online presence.
LinkedIn: Girish LinkedIn – Connect with me for professional insights, updates, and networking.
Ebasiq
Substack: ebasiq by Girish – In-depth articles on AI, Python, and technology trends.
Technical Blog: Ebasiq Blog – Dive into technical guides and coding tutorials.
GitHub Code Repository: Girish GitHub Repos – Access practical Python, AI/ML, Full Stack and coding examples.
YouTube Channel: Ebasiq YouTube Channel – Watch tutorials and tech videos to enhance your skills.
Instagram: Ebasiq Instagram – Follow for quick tips, updates, and engaging tech content.
GirishBlogBox
Substack: Girish BlogBlox – Thought-provoking articles and personal reflections.
Personal Blog: Girish - BlogBox – A mix of personal stories, experiences, and insights.
Ganitham Guru
Substack: Ganitham Guru – Explore the beauty of Vedic mathematics, Ancient Mathematics, Modern Mathematics and beyond.
Mathematics Blog: Ganitham Guru – Simplified mathematics concepts and tips for learners.