


How to Train Open-Source LLMs on Internal Enterprise Data: From RAG to Fine-Tuning
From RAG to Fine-Tuning — Understand the full spectrum of options to make Large Language Models (LLMs) smart with your internal data.

Why Customize LLMs with Your Internal Data?
While powerful open-source Large Language Models (LLMs) like LLaMA, Mistral, GPT-Neo, and Falcon have revolutionized natural language processing, their knowledge is derived solely from publicly available internet data. That makes them generalists — not specialists.
For organizations, this introduces critical limitations:
❌ They lack awareness of your proprietary documents — such as internal wikis, policy manuals, client SOPs, or historical reports.
❌ They fail to answer domain-specific or compliance-sensitive queries — such as those related to HR policies, financial workflows, or legal interpretations.
❌ They cannot be entrusted with mission-critical enterprise tasks that involve privacy, confidentiality, or regulatory boundaries.
To truly unlock the value of LLMs in enterprise environments, organizations need to bridge this knowledge gap by aligning these models with their internal datasets — including private documents, operational workflows, FAQs, communications, and structured records.
This alignment doesn’t always require full-scale model training. Instead, there’s a spectrum of adaptation techniques available — ranging from runtime data retrieval (like RAG) to lightweight fine-tuning (using PEFT/LoRA) and deep domain embedding (via supervised or continual training).
By applying the right strategy, you can transform a general-purpose LLM into a domain-aware assistant, support automation agent, or even a knowledge-driven decision-support system — purpose-built for your organization.
Ways to Train or Adapt LLMs for Local/Private/Org Data
Here's a progressive roadmap — from zero-training approaches to full-scale custom training:
1. Retrieval-Augmented Generation (RAG) — No Training Needed
🔹 Goal: Inject knowledge at runtime via external data sources.
🔹 How it works:
Chunk and embed your documents (e.g., PDFs, manuals).
Store in a vector store like FAISS/Chroma.
At runtime, retrieve top relevant chunks.
Inject them into the context window of the LLM.
# Pseudo-code
question = "How to approve reimbursements?"
context = retrieve_docs(question)
prompt = f"Answer based on context: {context}\n\nQuestion: {question}"
response = llm(prompt)
🔎 Example Use Case in Enterprise Context:
The Finance team wants to enable employees to query internal travel and reimbursement policies stored across hundreds of PDF documents. Without training an LLM, RAG can retrieve the right policy section and use it to answer:
“Can I claim meals on international travel?”
✅ Ideal for:
Fast deployment.
Frequently changing data.
Compliance-sensitive orgs (no LLM weight modification).
❌ Limitation:
Model still unaware of your data — it just “reads” it every time.
Bound by token limits.
2. Prompt Engineering + RAG (Hybrid Approach)
🔹 Goal: Guide LLM behavior while injecting knowledge dynamically.
Example Prompt:
SYSTEM_PROMPT = """
You are an AI assistant trained on ACME Corp's IT policies.
Answer questions using only the provided documents.
"""
Combine this with RAG context:
response = llm(f"{SYSTEM_PROMPT}\n\nContext: {retrieved_docs}\n\nUser: {query}")
🔎 Example Use Case in Enterprise Context:
The IT support team wants a smart assistant that responds only based on official company documentation — such as system access policies, VPN setup steps, or compliance requirements. A system prompt like “You are trained on ACME Corp’s policies only…” combined with RAG ensures controlled, accurate answers.
✅ Pros:
Easy to control tone and behavior.
No model tuning or infra cost.
❌ Cons:
Still not fine-tuned; doesn't generalize well.
3. Supervised Fine-Tuning (SFT) — Train the model on examples
🔹 Goal: Teach the model how to answer domain-specific queries using labeled examples.
🔹 Tools:
HuggingFace
transformers,datasets,accelerateModel: LLaMA, Mistral, Falcon (7B/13B)
🔹 Format (Alpaca-style):
{
"instruction": "Explain the KYC approval process",
"input": "",
"output": "To approve KYC, ensure PAN and Aadhaar match, then mark as verified in the system..."
}
🔎 Example Use Case in Enterprise Context:
The Customer Support team of a SaaS company has hundreds of labeled Q&A pairs like “How to reset my account password?” or “What is the refund policy for 30-day trials?” These examples are used to fine-tune an LLM to give consistent, automated responses without referencing external docs.
✅ Pros:
Great for custom task adaptation.
Works well for internal chatbots or support automation.
❌ Cons:
Requires good GPUs (A100/3090+).
Data labeling effort required.
4. Parameter-Efficient Fine-Tuning (PEFT) with LoRA/QLoRA
🔹 Goal: Reduce cost by tuning only small adapter layers, not full model.
🔹 Tools:
peft,transformers,bitsandbytes
🔹 Key Code Snippet:
from peft import get_peft_model, LoraConfig
peft_config = LoraConfig(task_type="CAUSAL_LM", r=8, lora_alpha=16)
model = get_peft_model(base_model, peft_config)
🔎 Example Use Case in Enterprise Context:
The Legal and Compliance team in a bank wants a chatbot that can interpret and respond to questions on internal audit procedures or regulation policies. By applying LoRA-based tuning on a 7B model using minimal labeled data, they build a low-cost, domain-aware assistant hosted internally.
✅ Pros:
Trainable on 1 GPU.
Only adapter weights are saved/shared.
Combine with quantization (4-bit/8-bit).
❌ Cons:
Requires understanding LoRA internals.
Still needs tuning data.
5. Instruction Tuning / Format Conditioning
🔹 Goal: Make the model behave consistently using instruction-response pairs.
🔹 Example Use Case:
“Always use formal tone”
“Always summarize in bullet points”
{
"instruction": "Summarize this employee policy in 3 bullet points",
"input": "Policy: Employees must log WFH days...",
"output": "- Log WFH daily\n- Manager approval\n- Email by 10 AM"
}
🔎 Example Use Case in Enterprise Context:
The HR team wants consistent tone and style in every response generated by their internal assistant — e.g., formal tone, short bullet points, and employee-friendly language. Instruction-tuning ensures uniformity like:
“Summarize leave policy in 3 bullet points.”
“Respond formally to questions about remote work.”
✅ Pros:
Makes outputs consistent with org tone.
Can be used with or without LoRA.
6. Continual Pretraining on Org Documents (Unlabeled)
🔹 Goal: Expand the model’s "vocabulary" and internal representation.
🔹 Use Case:
You have 10,000 PDFs or emails that don’t need labels.
Use as raw text and continue next-token prediction.
from transformers import DataCollatorForLanguageModeling
collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
trainer = Trainer(model, train_dataset, data_collator=collator)
🔎 Example Use Case in Enterprise Context:
A law firm or consulting company has a vast corpus of contracts, legal memos, and advisory reports that are not labeled. They continue pretraining an open-source LLM on this text to help the model better “understand” domain-specific language like clauses, disclaimers, and legal formats — even without direct supervision.
✅ Pros:
Model better understands your internal data structure.
Great for corpus adaptation.
❌ Cons:
Costly.
Needs clean, preprocessed data.
7. Multi-Modal Finetuning (Advanced)
🔹 Goal: Use data with text + images + tables.
Examples:
Internal reports, scanned forms, dashboards.
Tools: LLaVA, MiniGPT-4, OpenFlamingo.
🔎 Example Use Case in Enterprise Context:
The Internal Audit department receives scanned invoices, financial reports, and compliance documents as images or PDFs. Using a model like LLaVA or OpenFlamingo, they create a smart assistant that can read charts, tabular reports, and scanned signatures to answer audit-related queries like:
“What was the expense trend for Q2 in this scanned report?”
📘 Key Terminologies Explained
System Prompt
A fixed instruction provided to the LLM at the beginning of a conversation to guide its tone, behavior, or domain-specific context throughout the session.
Context Window
The maximum number of tokens (words, punctuation, symbols) that a language model can “see” at once to generate a response. All input data, instructions, and retrieved content must fit within this limit.
RAG (Retrieval-Augmented Generation)
A technique that combines a language model with an external knowledge base. Instead of training the model, it retrieves relevant documents at query time and uses them as context to answer questions.
Vector Store
A specialized database that stores document embeddings (numerical vector representations) and allows fast similarity-based search, often used in RAG setups. Examples include FAISS, Chroma, and Pinecone.
Fine-Tuning
The process of continuing model training using a specific dataset so the model can learn new patterns, tasks, or domains beyond its original training data.
Supervised Fine-Tuning (SFT)
A form of fine-tuning where the model is trained on pairs of input and expected output (labeled data), usually formatted as instruction–response tasks.
PEFT (Parameter-Efficient Fine-Tuning)
A set of techniques that enable training only a small number of additional parameters (like adapters or LoRA layers) instead of updating all weights in a large model — making training cheaper and faster.
LoRA (Low-Rank Adaptation)
A PEFT method that inserts lightweight adapter layers into a model’s architecture, allowing targeted fine-tuning by updating only these layers while keeping the main model weights frozen.
Quantization (4-bit/8-bit)
A model compression technique that reduces the precision of weights (e.g., from 16-bit to 4-bit), significantly lowering memory usage and enabling large models to run on smaller GPUs or CPUs.
Instruction Tuning
A method where LLMs are trained on tasks formatted as instructions and expected responses, making them follow commands more accurately and behave consistently.
Continual Pretraining
Extending a model’s original training by feeding it more unlabeled data, allowing it to better understand a specific domain or vocabulary without labeled supervision.
Multi-Modal Fine-Tuning
Training models to understand and generate responses using multiple input types (e.g., text + images + tables) to answer complex queries involving visual and textual elements.
Prompt Engineering
The practice of crafting prompts (instructions and inputs) in a structured way to guide the model's responses without modifying its internal weights.
📊 Comparison Table
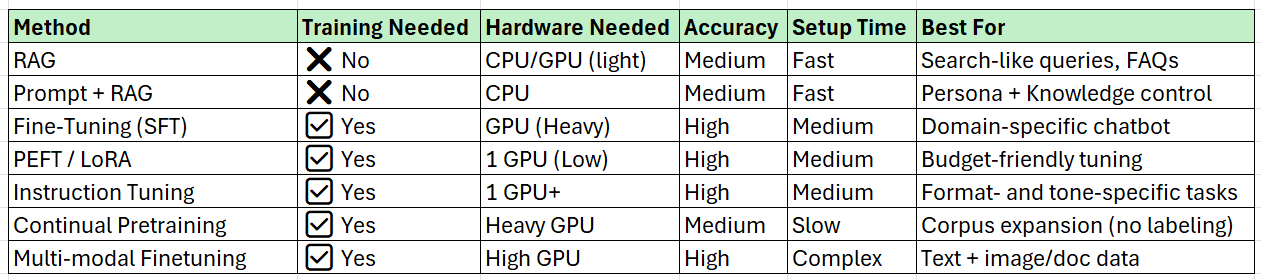
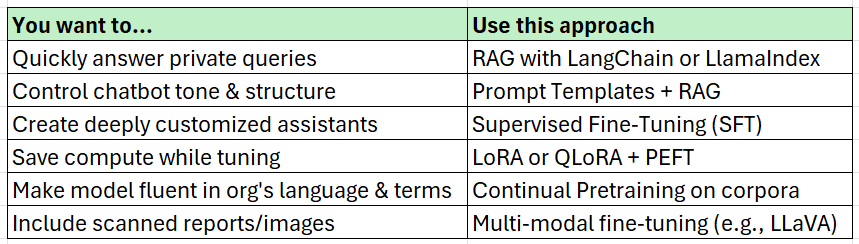
Conclusion: Choose the Right Method for Your Use Case
For more in-depth technical insights and articles, feel free to explore:
Girish Central
LinkTree: GirishHub – A single hub for all my content, resources, and online presence.
LinkedIn: Girish LinkedIn – Connect with me for professional insights, updates, and networking.
Ebasiq
Substack: ebasiq by Girish – In-depth articles on AI, Python, and technology trends.
Technical Blog: Ebasiq Blog – Dive into technical guides and coding tutorials.
GitHub Code Repository: Girish GitHub Repos – Access practical Python, AI/ML, Full Stack and coding examples.
YouTube Channel: Ebasiq YouTube Channel – Watch tutorials and tech videos to enhance your skills.
Instagram: Ebasiq Instagram – Follow for quick tips, updates, and engaging tech content.
GirishBlogBox
Substack: Girish BlogBlox – Thought-provoking articles and personal reflections.
Personal Blog: Girish - BlogBox – A mix of personal stories, experiences, and insights.
Ganitham Guru
Substack: Ganitham Guru – Explore the beauty of Vedic mathematics, Ancient Mathematics, Modern Mathematics and beyond.
Mathematics Blog: Ganitham Guru – Simplified mathematics concepts and tips for learners.